JVM内存区域全景解析:理解程序运行的底层舞台
每一个Java程序从启动到终止,都在JVM精心规划的内存舞台上运行。理解这片舞台的布局,是写出高性能、低内存消耗代码的前提。JVM在运行期间将内存划分为若干个功能各异的区域,每个区域承担着不同的职责,它们共同构成了Java程序运行的基础设施。
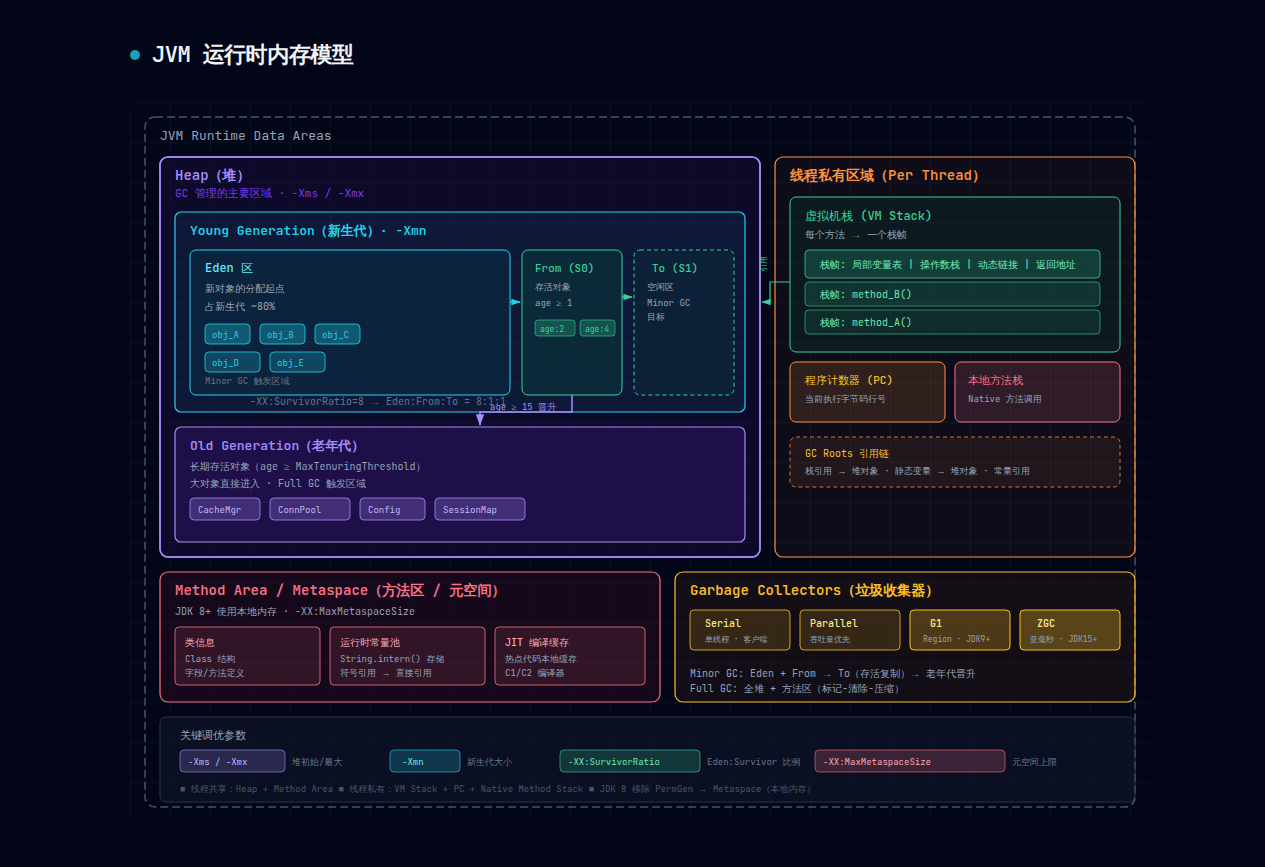
堆(Heap) 是JVM中面积最大的一块内存区域,几乎所有通过new关键字创建的对象和数组都栖息于此。堆是垃圾回收器管理的主战场,它被进一步细分为新生代(Young Generation)和老年代(Old Generation)。新生代又包含Eden区和两个Survivor区(From和To),这种精细划分直接服务于分代垃圾回收策略。堆的优势在于可以动态分配内存,对象的生命周期不必在编译期确定;但代价是运行时需要额外的管理开销,存取速度相比栈要慢一些。
栈(Stack) 则存放着方法执行时的局部变量——包括基本数据类型(int、long、double等)的值以及对象的引用。每当一个方法被调用,JVM就会在栈中压入一个新的栈帧(Stack Frame),其中包含局部变量表、操作数栈、动态链接和返回地址等信息。方法执行完毕后,对应的栈帧自动弹出,内存随即释放,无需垃圾回收介入。栈的存取速度极快,仅次于CPU寄存器,但它要求数据的大小和生命周期在编译时就是确定的,灵活性不如堆。
方法区(Method Area) 存放已被加载的类信息、常量池、静态变量以及即时编译器编译后的代码。在HotSpot JVM的早期实现中,这块区域被称为"永久代"(PermGen),后来被"元空间"(Metaspace)取代,后者直接使用本地内存而非JVM堆内存,避免了永久代频繁溢出的问题。
程序计数器(Program Counter Register) 是一块极小的内存,记录着当前线程正在执行的字节码指令的地址。如果是执行的是一个本地方法,则这个计数器的值为undefined。它是线程私有的,每个线程都有自己独立的程序计数器。
本地方法栈(Native Method Stack) 为JVM调用本地方法(通常是用C/C++编写的方法)服务,其工作机制与虚拟机栈非常相似,只不过它管理的是本地方法的调用状态。
堆与栈的深度对比:分配策略与性能差异
堆和栈的区别远不止"一个存对象、一个存引用"这么简单。理解它们的分配策略差异,对于编写内存友好的代码至关重要。
栈有一个非常重要的特性——数据共享。假设我们同时定义两个整型变量:
| |
编译器在处理int a = 3时,首先在栈中创建变量a的引用,然后检查栈中是否已存在值为3的数据。如果没有,就将3存入栈中,并让a指向它。接着处理int b = 3时,由于栈中已有值为3的数据,便直接让b也指向同一个地址。当执行a = 4时,编译器会搜索栈中是否有4,没有则存入新值并让a指向它——b的值不受任何影响。这种共享是编译器层面的优化,与两个引用指向同一个堆对象的共享机制完全不同。
堆中的对象分配则走的是另一条路径。当我们用new创建对象时,JVM在堆中为其分配空间,并在栈中保存指向该对象的引用。即使创建该对象的代码块已经执行完毕,只要还有引用指向它,堆中的对象就不会被回收。只有当所有引用都消失后,对象才变成垃圾回收器的目标。这种"引用延迟释放"的机制是Java比较占内存的原因之一,但也正是自动内存管理的基础。
从性能角度看,栈分配的速度远远快于堆分配。栈的分配和释放只是一个指针移动的操作(栈顶指针上移或下移),而堆分配需要搜索空闲内存、维护分配表,还可能触发垃圾回收。因此在实际开发中,对于生命周期短且大小确定的数据,应尽量利用栈分配;对于需要跨方法传递、生命周期较长的对象,才使用堆分配。
常量池与方法区:字符串驻留机制的奥秘
常量池是Java内存模型中一个容易被忽视却影响深远的区域。它在编译期被确定,保存在.class文件中,除了包含代码中定义的各种基本类型常量值之外,还包含以文本形式出现的符号引用——类和接口的全限定名、字段的名称和描述符、方法的名称和描述符等。当类被加载时,常量池随之进入方法区。
对于String类型,常量池的行为尤为值得关注。JVM为String维护了一张专用的表,存储文字字符串的值。这意味着相同的字符串常量在内存中只存在一份拷贝,这种机制被称为字符串驻留(String Interning)。
理解String的两种创建方式的区别,是掌握常量池机制的关键:
| |
第一种方式,JVM先在栈中创建引用变量str1,然后到字符串常量池中查找是否已有"abc"。如果有,直接让str1指向它;如果没有,则在常量池中创建"abc"并让str1指向它。第二种方式则直接在堆中创建一个新的String对象,不管常量池中是否已有相同值的字符串。因此,str1 == str2的结果为false——它们指向不同的内存地址。
当多个字符串通过字面量拼接时(如"a" + "b" + "c"),编译器会在编译期就将其优化为"abc",最终结果仍然是常量池中的引用。但如果拼接中包含变量引用(如a + b + c,其中a、b、c是String变量),JVM只能在运行时通过StringBuilder来动态拼接,生成的是一个全新的堆对象。这就是为什么在循环中拼接字符串时应使用StringBuilder而非+运算符的根本原因——每次+都会创建和销毁一个StringBuilder对象,造成大量无谓的内存开销。
String.intern()方法可以手动将运行时创建的字符串注册到常量池中。调用该方法时,JVM检查常量池中是否已存在相同Unicode值的字符串,如果有则返回其引用,如果没有则将当前字符串的值加入常量池并返回引用。这在处理大量重复字符串的场景下(如解析文本数据)能有效减少内存占用。
垃圾回收算法详解:从标记清除到分代收集
垃圾回收(Garbage Collection,GC)是Java自动内存管理的核心。它的根本任务是识别并释放那些不再被引用的对象所占用的内存。理解GC的工作原理,是进行有效调优的基础。
标记-清除算法(Mark-Sweep) 是最基础的垃圾回收算法。它分为两个阶段:标记阶段从一组根对象(GC Roots)出发,沿着引用链递归遍历所有可达对象并做标记;清除阶段扫描整个堆,释放所有未被标记的对象所占的内存。这种算法简单直接,但会产生内存碎片——被释放的内存空间不连续,可能导致大对象无法分配而提前触发Full GC。
标记-压缩算法(Mark-Compact) 在标记-清除的基础上增加了压缩阶段。标记完成后,将所有存活对象向内存的一端移动,然后清理边界以外的全部空间。这消除了内存碎片问题,但移动对象的代价不低,尤其是在老年代中对象数量庞大时。
复制算法(Copying) 将内存分为两个等大的区域,每次只使用其中一个。垃圾回收时,将存活对象复制到另一个区域,然后一次性清空当前区域。这种方法天然解决了碎片问题,分配内存只需移动指针即可,非常高效。缺点是可用内存只有总量的一半,而且对于长生命周期的对象,反复复制的开销不可小觑。
分代收集(Generational Collection) 是当代JVM采用的主流策略,它基于一个经过大量实践验证的经验假说:绝大多数对象都是朝生夕灭的。基于这一假说,JVM将堆划分为新生代和老年代。新生代中对象更新极快,适合使用复制算法;老年代中对象相对稳定,适合使用标记-压缩或标记-清除算法。新生代又被细分为Eden区(对象诞生的地方)和两个Survivor区(From和To),Minor GC时将Eden中存活的对象复制到空的Survivor区,From和To的角色在每次GC后互换。当对象在Survivor区中经历足够多次GC后(年龄达到阈值),就会被晋升到老年代。
G1与ZGC:现代垃圾收集器的设计哲学
随着应用对低延迟的要求越来越高,传统的分代收集器(如Parallel Old GC)在大堆场景下的长时间停顿成了瓶颈。G1(Garbage-First)和ZGC应运而生,它们代表了GC设计的两个不同方向。
G1收集器将整个堆划分为大量大小相等的Region(默认约2048个),每个Region可以动态充当Eden、Survivor、Old或Humongous(大对象专用)角色。G1的核心思想是优先回收收益最大的Region——它维护一个按回收价值排序的列表,在用户设定的停顿时间目标(通过-XX:MaxGCPauseMillis控制,默认200ms)内,选择回收收益最高的Region进行收集。G1的Mixed GC可以同时回收新生代和部分老年代Region,避免了传统收集器中Full GC的全堆扫描。G1通过"快照-复制"的方式在Region之间移动对象,在并发标记阶段利用SATB(Snapshot-At-The-Beginning)算法与应用程序并发执行,大幅减少了停顿时间。
ZGC(Z Garbage Collector) 则将目标推向了极致——亚毫秒级停顿。它通过两项关键技术实现这一目标:着色指针(Colored Pointers)利用指针中的空闲位标记对象状态,避免了传统标记算法需要额外内存和停顿的问题;读屏障(Load Barrier)在应用线程读取引用时检查指针颜色,实现了标记和应用线程的完全并发。ZGC的停顿几乎只发生在根扫描阶段,且耗时通常不超过1毫秒,无论堆的大小如何。这使得ZGC特别适合对延迟极其敏感的场景,如高频交易系统、实时推荐引擎等。
JVM调优核心参数:从理论到实践的调参指南
理论再精妙,最终都要落地到JVM启动参数上。以下是一组在实际生产环境中最常用的调优参数,理解它们的含义和相互关系,才能做出精准的调整。
堆大小控制: -Xms设置堆的初始大小,-Xmx设置堆的最大值。在生产环境中,通常将两者设为相同的值,避免堆在运行时频繁扩容和收缩带来的性能波动。例如-Xms4g -Xmx4g表示堆大小固定为4GB。
新生代控制: -Xmn直接设置新生代大小。也可以通过-XX:NewRatio设置新生代与老年代的比例,NewRatio=2表示新生代占堆的1/3。对于创建大量短生命周期对象的应用,适当增大新生代可以减少Minor GC频率,但过大会挤压老年代空间,导致更频繁的Full GC。
Survivor区控制: -XX:SurvivorRatio控制Eden与一个Survivor区的比值。例如SurvivorRatio=8表示Eden:Survivor=8:1,新生代中Eden占80%,两个Survivor各占10%。这个参数的调整需要结合实际的对象存活率来定。
晋升阈值控制: -XX:MaxTenuringThreshold设置对象在Survivor区中经历多少次GC后晋升到老年代,默认值为15。如果应用中有大量中等生命周期的对象,适当降低此值可以让它们更快进入老年代,减少在Survivor区中的复制开销。设为0则完全跳过Survivor区,对象直接从Eden进入老年代。
GC选择: 通过-XX:+UseG1GC启用G1收集器,-XX:+UseZGC启用ZGC。G1场景下,-XX:MaxGCPauseMillis=200设置期望的最大停顿时间,JVM会自动调整Region大小和回收策略来尽量满足目标。
一个典型的生产环境配置示例:
| |
这组参数将堆固定为4GB,新生代1GB,Survivor区占比合理,使用G1收集器并设置200ms停顿目标,同时输出详细的GC日志用于后续分析。
JVM监控工具链:让内存问题无处遁形
调优的前提是观测。JDK自带了一系列强大的诊断工具,配合第三方工具可以构建完整的JVM监控体系。
jstat 是命令行下最轻量的GC监控工具。jstat -gcutil <pid> 1000每秒输出一次GC统计摘要,包括各区域的使用率、GC次数和耗时。通过观察Eden使用率的增长速度和Minor GC的频率,可以快速判断新生代大小是否合理。如果Minor GC过于频繁,说明新生代偏小或对象分配速率过高;如果Old区使用率持续增长,可能存在内存泄漏。
jmap 用于生成堆的快照(Heap Dump)。jmap -dump:format=b,file=heap.hprof <pid>会将当前堆的完整状态导出为二进制文件。这个文件可以导入Eclipse MAT(Memory Analyzer Tool)进行离线分析,MAT能自动识别可疑的内存泄漏点,展示对象的引用链和dominator tree,帮助快速定位问题根源。
VisualVM 是一个集成的可视化监控工具,提供CPU和内存的实时监控、线程状态查看、GC活动可视化等功能。它的"Sampler"和"Profiler"模块可以采样分析方法的执行时间和内存分配热点,帮助发现性能瓶颈。对于远程JVM,通过JMX连接即可实现远程监控。
GC日志分析是深层次调优的重要手段。通过-Xlog:gc*:file=gc.log(JDK 11+)或-XX:+PrintGCDetails(JDK 8)输出详细GC日志,然后使用GCViewer或GCEasy等工具进行可视化分析。关注的关键指标包括:Minor GC平均耗时、Full GC频率和耗时、GC前后的堆使用量变化、晋升到老年代的对象大小趋势等。
常见内存泄漏模式与排查策略
虽然Java有自动垃圾回收机制,但内存泄漏仍然可能发生——当程序持有对无用对象的引用时,GC无法回收这些对象,内存就会持续增长直到OOM。
集合类持有引用是最常见的泄漏模式。将对象放入HashMap、ArrayList等集合后,如果忘记在使用完毕后将其移除,即使对象本身已经无用,集合仍然持有其强引用。典型的场景是缓存实现中没有设置淘汰策略,数据只进不出,最终撑爆内存。解决方案是使用WeakHashMap、设置TTL过期机制,或者使用Guava Cache、Caffeine等成熟的缓存框架。
静态变量持有大对象是另一种隐蔽的泄漏。静态变量的生命周期与JVM进程相同,一旦被赋值就不会被GC回收。如果静态集合不断添加元素而不清理,内存会持续增长。排查时需要重点关注代码中的静态Map、List等集合,确保有合理的清理机制。
未关闭的资源也是泄漏的温床。数据库连接、网络Socket、文件句柄等资源如果不正确关闭,不仅占用系统资源,其关联的对象也无法被GC回收。Java 7引入的try-with-resources语法可以有效避免这类问题。
ThreadLocal使用不当在线程池场景下尤其危险。线程池中的线程是复用的,如果ThreadLocal中存储的值没有在任务结束时调用remove()方法清理,下一个任务可能读到上一个任务遗留的数据,同时这些数据也因线程的长期存活而无法被回收。
监听器和回调未注销同样会导致泄漏。在GUI应用或事件驱动的架构中,注册了事件监听器但忘记注销,被监听的对象会持有对监听器的引用,导致监听器及其关联的对象图无法被回收。
排查内存泄漏的一般流程是:首先通过监控工具发现内存持续增长的趋势;然后在合适的时机导出Heap Dump;使用MAT等工具分析大对象和可疑引用链;最后定位到具体的代码行并修复。预防胜于治疗,在开发阶段就应养成良好的资源管理习惯——用完即释放、缓存设上限、资源要关闭。
从JVM的内存区域划分到垃圾回收算法的演进,从调优参数的精细控制到监控工具的有效运用,Java内存管理是一条贯穿整个应用生命周期的技术链路。真正掌握这条链路,不在于记住每一个参数的默认值,而在于理解每个设计决策背后的权衡——时间与空间的权衡、吞吐量与延迟的权衡、简单性与灵活性的权衡。当你在生产环境中面对一次Full GC或一个OOM异常时,这些理解会转化为直觉,引导你快速定位问题并给出精准的解决方案。技术的深度,往往就藏在这些看似枯燥的底层细节之中。